A study on Social Dilemmas with Multi Agent Reinforcement Learning.
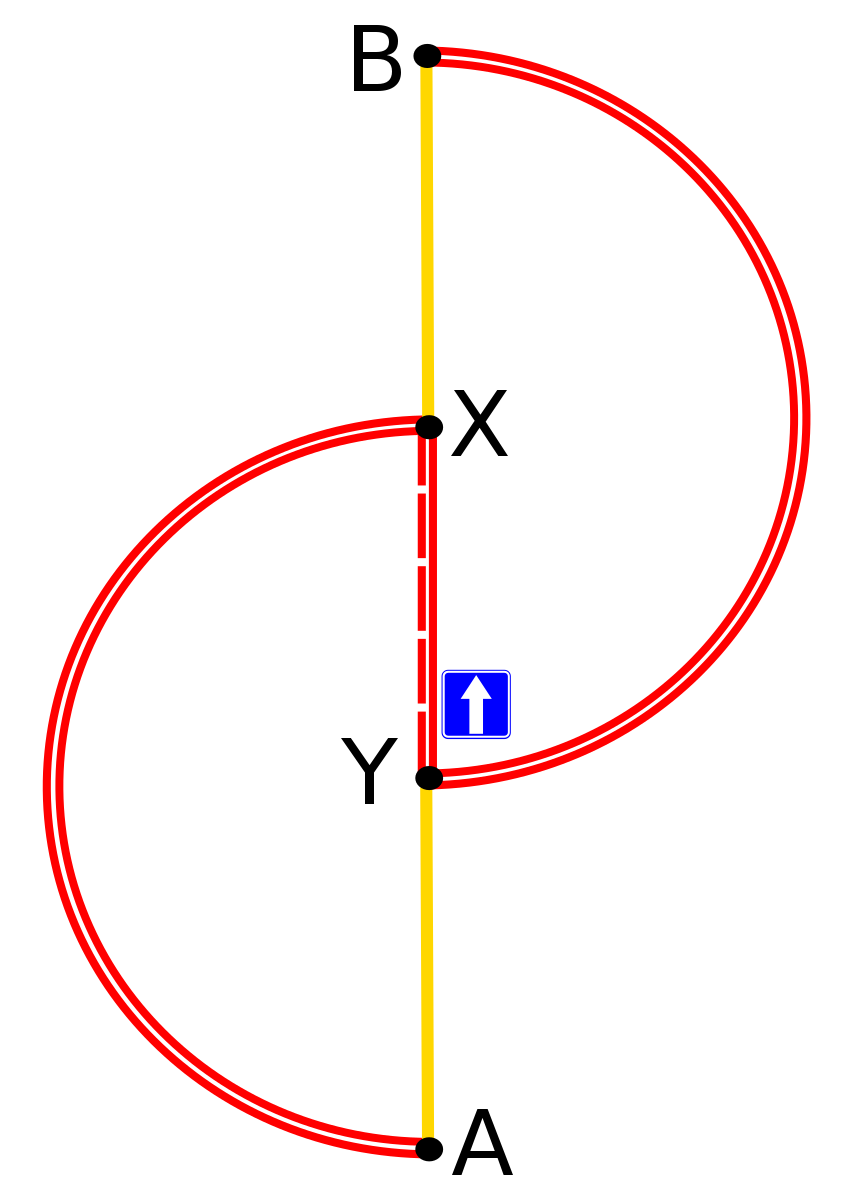
An example on a Braess Paradox game environment




%load_ext autoreload
%autoreload 2
import numpy as np
from collections import defaultdict
from random import random
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
import sys
sys.path.append('../')
from Agents import QAgent
from Environments import BraessParadoxEnv, BraessParadoxGymEnv
from visualization_tools import *
import itertools
N = 400
#actions = {seq for seq in itertools.product("01", repeat=N)} (# too expensive)
from math import factorial
print(factorial(N)/factorial(N-2))
from random import random
actions_sample = ['A' if random()>0.5 else 'B' for x in range(N)]
print(actions_sample[:10])
T = sum([a=='A' for a in actions_sample])
print(T)
rewards = [T/100 if a=='A' else 45 for a in actions_sample]
print(rewards[:10])
states = {}
states['Start'] = {'S': N, 'A': 0, 'B': 0, 'E': 0}
for t in range(N+1):
states[str(t)] = {'S': 0, 'A': t, 'B': N - t, 'E': 0}
states['End'] = {'S': 0, 'A': 0, 'B': 0, 'E': N}
states[str(T)]
states = {}
for i in range(N+1):
for step in {0, 1}:
for position in {'S', 'A', 'B'}:
states[(position, step, i, N-i)] = 0.0
env = BraessParadoxEnv(n_agents=400)
new_state = env.reset()
new_state['step'], new_state['actions'][0]
env = BraessParadoxGymEnv(n_agents=400)
new_state = env.reset()
new_state['step'], new_state['positions'][0]
env.n_agents
env.social_welfare_type
env.cost_params
sample_actions = ['A' if random() > 0.5 else 'B' for x in range(4000)]
new_state, rewards, done, info = env.step(sample_actions)
sample_actions[0], new_state['step'], new_state['positions'][0], rewards[0], done
sample_actions = ['B' if (a == 'A') and (random() > 0.5) else a for a in sample_actions]
new_state, rewards, done, info = env.step(sample_actions)
sample_actions[0], new_state['step'], new_state['positions'][0], rewards[0], done
env = BraessParadoxGymEnv(n_agents=400)
n_agents = env.n_agents
new_state = env.reset()
new_state['step'], new_state['positions'][0]
params = {'lr': 0.005,
'gamma': 0.999,
'eps_start': 1.0,
'eps_end': 0.001,
'eps_dec': 0.995}
agents = [QAgent(**params, id_agent=i) for i in tqdm(range(n_agents))]
agents[0].choose_action(new_state)
actions = [agents[i].choose_action(new_state) for i in tqdm(range(env.n_agents))]
actions[0]
new_state, rewards, done, info = env.step(actions)
new_state['positions'][0], rewards[0], done
actions = [agents[i].choose_action(new_state) for i in tqdm(range(env.n_agents))]
actions[0]
state = new_state
new_state, rewards, done, info = env.step(actions)
new_state['positions'][0]
def run_experiment(config, verbose=True):
n_agents = config['n_agents']
social_welfare_type = config['social_welfare_type']
n_episodes = config['n_episodes']
agent_params = config['agent_params']
agent_type = config['agent_type']
env = BraessParadoxGymEnv(n_agents=n_agents, social_welfare_type=social_welfare_type)
agents = [eval(agent_type)(**agent_params, id_agent=i) for i in tqdm(range(n_agents))]
# Intialization
scores = defaultdict(list)
win_pct_list = []
cooperations = []
qvalues = []
actions_list = []
for i_episode in tqdm(range(n_episodes)):
actions_episode = []
done = False
state = env.reset()
scores_episode = defaultdict(int)
while not done:
actions = [agents[i].choose_action(state) for i in range(n_agents)]
new_state, rewards, done, info = env.step(actions)
for id_agent in range(n_agents):
agents[id_agent].learn(state, actions[id_agent], rewards[id_agent], new_state)
scores_episode[id_agent] += rewards[id_agent]
state = new_state
actions_episode.append(actions)
actions_list.append(actions_episode)
qvalues.append(agents[0].Q)
for id_agent in range(n_agents):
scores[id_agent].append(scores_episode[id_agent])
if verbose and i_episode % 100 == 0:
mean_scores = [np.mean(scores[i][-100:]) for i in range(n_agents)]
print('episode ', i_episode,
'\n Mean Reward Agent 1 %.2f' % mean_scores[0],
'\n epsilon %.2f \n' % agents[0].epsilon,
'-'*100)
report = {'scores': scores,
'actions_list': actions_list,
'qvalues': qvalues}
return report
experiment_config = {
'n_episodes': 1000,
'n_agents': 400,
'social_welfare_type': None,
'agent_type': 'QAgent',
'agent_params': {
'lr': 0.005,
'gamma': 0.999,
'eps_start': 1.0,
'eps_end': 0.001,
'eps_dec': 0.995
}
}
report = run_experiment(experiment_config)
scores = report['scores']
actions_list = report['actions_list']
plot_scores(scores)

plot_actions(actions_list)
